Les archives de Kermith72
MySQL
Dépannage du partionnement Centreon
02/11/19 22:55 Classé dans: Techniques
Malheureusement, le lendemain, patatras ! De nouveaux des alertes de cpu et de charge processeur ! Bon, il faut reconnaître que la machine me sert qu'à des fins de tests et que je ne m'en occupe pas tous les jours. Cette machine Après quelques recherches sur l'IHM de Centreon, je découvre le graphe suivant.
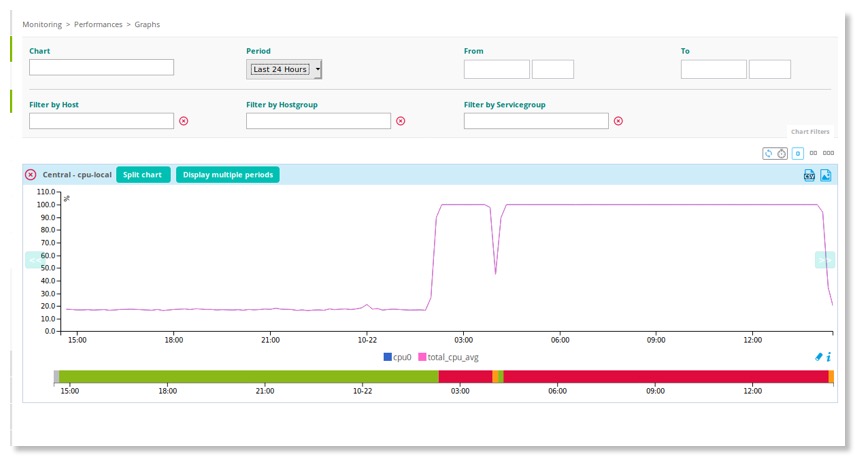
Je constate que le cpu s'affole à 2 H 00 du matin correspondant au cron de purge des logs et data-bin de la base centreon_storage. Le constat est sans appel, il s'agit d'un problème de base de données et plus précisément du partitionnement. La copie d'écran ci-dessous me confirme mon raisonnement.
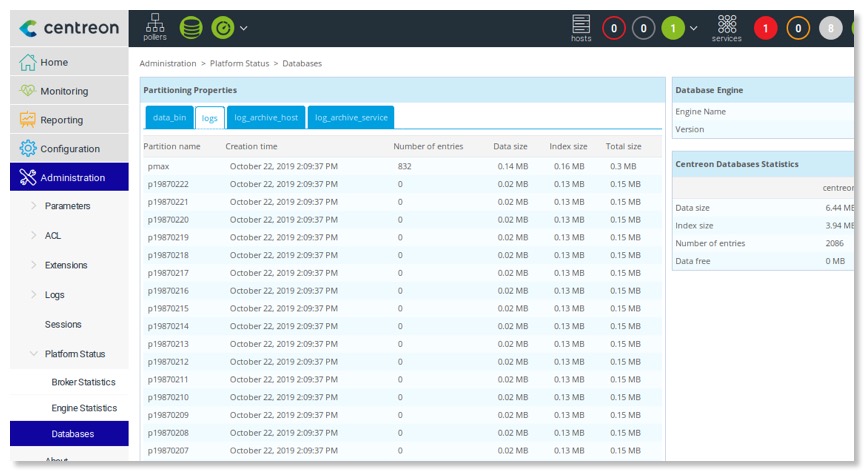
Les partitions de la table logs ont une date périmée (1987), il devrait avoir des partitions avec une date plus récente avec 10 jours d'avance sur la date du jour. Bilan : les tables logs, log_archive_host et log_archive_service ne sont pas à jour en termes de partitionnement.
Pour corriger ce dysfonctionnement, une solution : refaire le partitionnement des tables incriminées. Mais attention, pour réaliser cette opération, assurez-vous d'avoir suffisamment d'espace disque pour MySQL ou MariaDB. En effet il faut un espace libre équivalent à deux fois et demie de la table existante.
Voici la procédure à appliquer pour chaque table, nous prenons pour exemple la table logs :
Supprimez les partitions de la table logs, attention cela peut prendre du temps surtout avec des tables importantes.
mysql -u centreon -p centreon_storage
MariaDB [centreon_storage]> ALTER TABLE logs REMOVE PARTITIONING;
exemple du résultat de la fin d'un partitionnement
Query OK, 832 rows affected (48 min 21.14 sec)
Records: 832 Duplicates: 0 Warnings: 0
MariaDB a enlevé les partitions de la table logs.
Maintenant, il faut refaire le partitionnement de cette table, nous allons reprendre le script suivant suivant la distribution.
Debian et Ubuntu
/usr/bin/php /usr/share/centreon/bin/centreon-partitioning.php -m logs
CentOS 7
/opt/rh/rh-php72/root/usr/bin/php /usr/share/centreon/bin/centreon-partitioning.php -m logs
vous devriez avoir ce résultat
[Sat, 20 Feb 21 09:42:39 +0100] PARTITIONING STARTED
[Sat, 20 Feb 21 09:42:39 +0100][migrate] Renaming table centreon_storage.logs TO centreon_storage.logs_old
[Sat, 20 Feb 21 09:42:39 +0100][migrate] Creating parts for new table centreon_storage.logs
[Sat, 20 Feb 21 09:47:37 +0100][migrate] Insert data from centreon_storage.logs_old to new table
[Sat, 20 Feb 21 09:47:38 +0100] PARTITIONING COMPLETED
Ensuite, supprimez la table logs_old créé lors du partionnement de la table logs.
mysql -u centreon -p centreon_storage
MariaDB [centreon_storage]> drop table logs_old;
Répétez ces opérations pour les tables impactées. Point d'attention, l'espace utilisé pour supprimer les anciennes partitions ne sera pas récupéré.
Et ma supervision Centreon est repartie de plus belle
Gérer le partitionnement de vos VM de test
21/05/17 17:12 Classé dans: Techniques
Malheureusement mes VM ne sont pas en fonctionnement à 4 heures du matin et si vous avez comme moi activer la supervision du Central, vous obtenez l'alerte suivante :

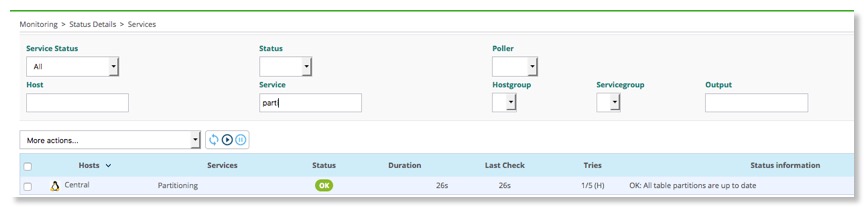
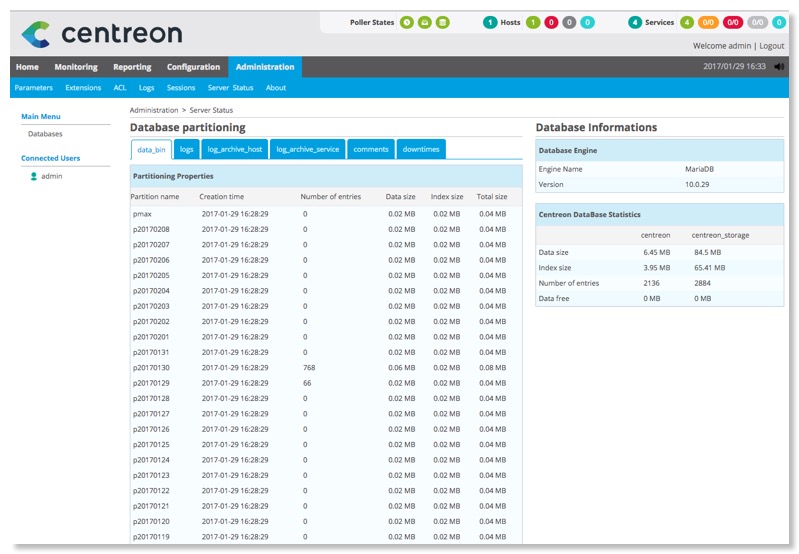
En vérifiant l'état des bases avec le menu Administration -> Server Status, on constate que le système n'a pas anticipé le partionnement des tables basé sur les dates. Nous devrions être à J+10 normalement.
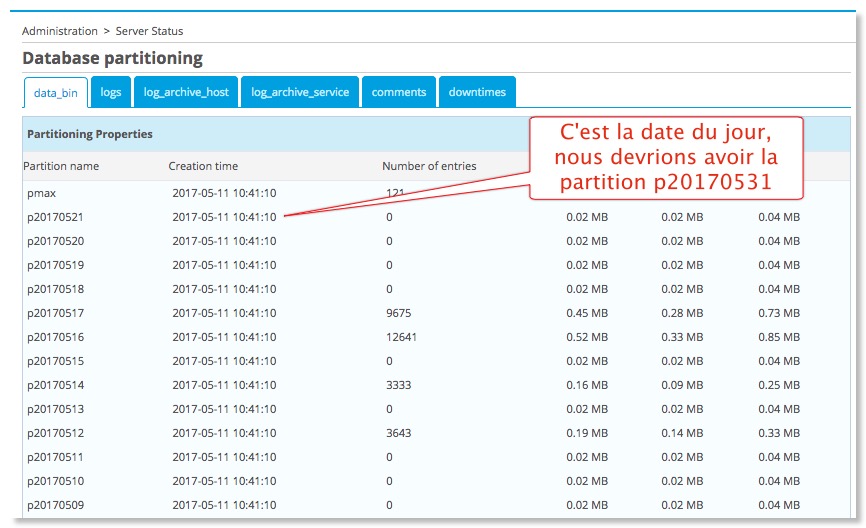
Pour forcer la gestion du partionnement, connectez-vous en invite de commande sur le serveur de supervision et procédez aux commandes suivantes :
su - centreon
/usr/bin/php /usr/share/centreon/cron/centreon-partitioning.php >> /var/log/centreon/centreon-partitioning.log
Vous pouvez vérifier de nouveau l'état de partitionnement de vos tables
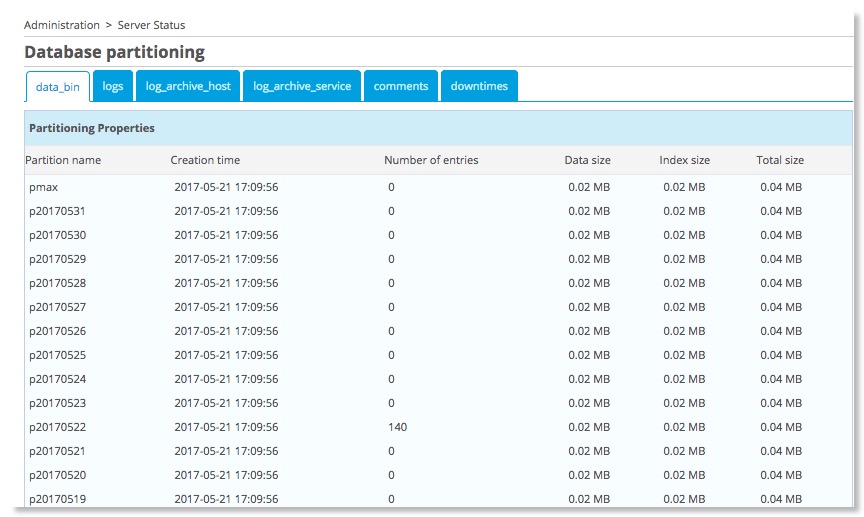
Et le service revient à l'état OK
Le partitionnement BDD et Centreon
29/01/17 21:06 Classé dans: Techniques
Et pour finir un upgrade de mes articles sur Centreon avec Debian avec la nouvelle version 2.8.3 et centreon-engine 1.7.0 : Full Centreon 2.8 et Maj Full Centreon 2.7x -> 2.8.
Les plugins Centreon et MySQL
13/06/14 12:09 Classé dans: Techniques
MAJ 13/06/2014 : Mise à jour de l'article du plugin check_mysql_health et du plugin centreon pour MySQL, vous pourrez comparer les différents plugins mis à votre disposition.
Quand innoDB nous fait des misères....
18/03/15 06:55 Classé dans: Techniques
C'était lundi noir cette semaine  Mon MacBook est parti en vrille avec occupation excessive de la mémoire ce qui a provoqué un crash du système. Et lors du redémarrage de ma VM Centreon, j'ai eu la désagréable surprise du message suivant :
Mon MacBook est parti en vrille avec occupation excessive de la mémoire ce qui a provoqué un crash du système. Et lors du redémarrage de ma VM Centreon, j'ai eu la désagréable surprise du message suivant :
Grosse galère ! après quelques recherches sur le net, voici ma procédure pour résoudre ce problème. Je ne vous souhaite pas cette mésaventure, mais oui, vous avez une infrastructure redondée, ultra-sécurisée avec une sauvegarde d'enfer mais on ne sait jamais, vous en aurez peut-être besoin. D'autant qu'il n'est pas facile de réfléchir sereinement lorsque la catastrophe arrive !
mais on ne sait jamais, vous en aurez peut-être besoin. D'autant qu'il n'est pas facile de réfléchir sereinement lorsque la catastrophe arrive !
Avant touche chose, sauvegardez vos bases MySQL. Vérifiez bien que vous avez assez d'espace disponible. Nous allons sauvegarder le datadir (par défaut sur Debian /var/lib/mysql) sur un autre espace.
En modifiant le fichier de configuration /etc/mysql/my.cnf, nous ajoutons l'instruction suivante :
Nous tentons de démarrer MySQL
Si le démarrage échoue, augmentez la valeur innodb_force_recovery de 1 et recommencez. Attention, quand vous arrivez à la valeur de 3, rajoutez l'instruction suivante :
Normalement MySQL devrait démarrer, si ce n'est pas le cas, désolé pour vous
Une fois MySQL démarré, vérifiez les tables.
Tout est OK, il faut passer à la sauvegarde des données.
Sauvegardez vos données afin de les réinjecter quand MySQL sera réparé. Attention à l'espace disque si vous avez beaucoup de données.
Avant de réinstaller MySQL, arrêtez la base de données. A ce stade, je n'ai pas trouvé mieux que la commande kill, car en utilisant la commande d'arrêt normal, MySQL met deux "plombes" à s'arrêter.
On vérifie les processus de MySQL.
Et on joue à l'admin system fou en killant les processus
On supprime MySQL.
On enlève les instructions innodb dans le fichier de configuration /etc/mysql/my.cnf. On supprime les données dans le datadir pour faire place nette.
On installe de nouveau MySQL.
On restaure les données de MySQL.
Votre basse de données doit fonctionner de nouveau.
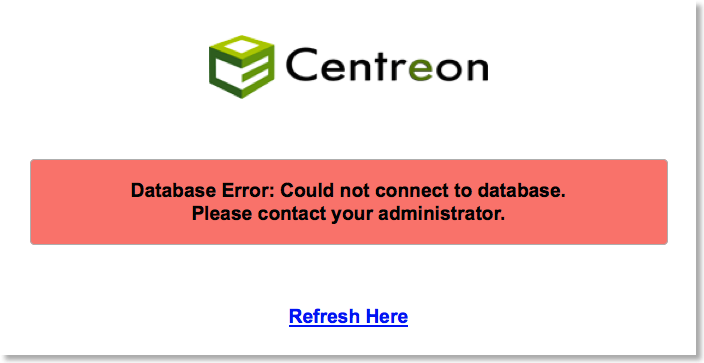
Catastrophe, en y regardant de plus près, le service MySQL est arrêté. Une petite vérification des logs et le constat suivant, la base du moteur InnoDB est crashée :
Mar 16 16:11:24 central mysqld: 150316 16:11:24 InnoDB: Waiting for the background threads to start
Mar 16 16:11:24 central mysqld: InnoDB: Starting in background the rollback of uncommitted transactions
Mar 16 16:11:24 central mysqld: 150316 16:11:24 InnoDB: Rolling back trx with id 1278E, 1 rows to undo
Mar 16 16:11:24 central mysqld: 150316 16:11:24 InnoDB: Assertion failure in thread 140567022315264 in file fut0lst.ic line 83
Mar 16 16:11:24 central mysqld: InnoDB: Failing assertion: addr.page == FIL_NULL || addr.boffset >= FIL_PAGE_DATA
Grosse galère ! après quelques recherches sur le net, voici ma procédure pour résoudre ce problème. Je ne vous souhaite pas cette mésaventure, mais oui, vous avez une infrastructure redondée, ultra-sécurisée avec une sauvegarde d'enfer
1 sauvegarde du datadir
Avant touche chose, sauvegardez vos bases MySQL. Vérifiez bien que vous avez assez d'espace disponible. Nous allons sauvegarder le datadir (par défaut sur Debian /var/lib/mysql) sur un autre espace.
cd /var/lib
cp -vpr mysql mysql-backup
2 tentative de redémarrage MySQL
En modifiant le fichier de configuration /etc/mysql/my.cnf, nous ajoutons l'instruction suivante :
innodb_force_recovery = 1
Nous tentons de démarrer MySQL
service mysql start
Si le démarrage échoue, augmentez la valeur innodb_force_recovery de 1 et recommencez. Attention, quand vous arrivez à la valeur de 3, rajoutez l'instruction suivante :
innodb_purge_threads = 0
Normalement MySQL devrait démarrer, si ce n'est pas le cas, désolé pour vous
3 Test des tables
Une fois MySQL démarré, vérifiez les tables.
mysqlcheck -u root -ppass --all-databases
Tout est OK, il faut passer à la sauvegarde des données.
4 Sauvegarde des données
Sauvegardez vos données afin de les réinjecter quand MySQL sera réparé. Attention à l'espace disque si vous avez beaucoup de données.
mysqldump -u root -ppass --all-databases > /home/vmdebian/alldbs.sql
5 Arrêt de MySQL
Avant de réinstaller MySQL, arrêtez la base de données. A ce stade, je n'ai pas trouvé mieux que la commande kill, car en utilisant la commande d'arrêt normal, MySQL met deux "plombes" à s'arrêter.
On vérifie les processus de MySQL.
ps aux | grep mysql
root 7914 0.0 0.0 4180 720 pts/0 S 08:45 0:00 /bin/sh /usr/bin/mysqld_safe
mysql 8277 1.8 8.1 369888 82712 pts/0 Sl 08:45 0:01 /usr/sbin/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib/mysql/plugin --user=mysql --pid-file=/var/run/mysqld/mysqld.pid --socket=/var/run/mysqld/mysqld.sock --port=3306
root 8278 0.0 0.0 5588 712 pts/0 S 08:45 0:00 logger -t mysqld -p daemon.error
root 8555 0.0 0.0 7848 884 pts/0 S+ 08:47 0:00 grep mysql
Et on joue à l'admin system fou en killant les processus
kill -9 7914
kill -9 8277
6 Suppression de MySQL
On supprime MySQL.
apt-get remove --purge mysql-server-5.5
On enlève les instructions innodb dans le fichier de configuration /etc/mysql/my.cnf. On supprime les données dans le datadir pour faire place nette.
7 Installation de MySQL
On installe de nouveau MySQL.
apt-get install mysql-server
8 Restauration des données
On restaure les données de MySQL.
mysql -u root -ppass < /home/vmdebian/alldbs.sql
Votre basse de données doit fonctionner de nouveau.
Dernière modification: 30/07/2023